《数据科学实战/Doing Data Science》摘记
背景
从事数据统计工作,一直想在数据科学方面有所进展,《数据科学实战》提供了一些知识结构和从业经验,值得学习。
摘记
知识构成与建模经验
知识构成
数据科学家:
- 从数据中抽取信息并且解释数据背后的意义 –> 统计学、机器学习
- 采集、清理和处理数据 –> 统计学和软件工程
- 结合可视化和数据的意义进行探索分析,找出模式,构建模型,设计算法
- 设计实验,基于数据做出决策
- 数据报告和交流,包括组内成员、工程师、领导层
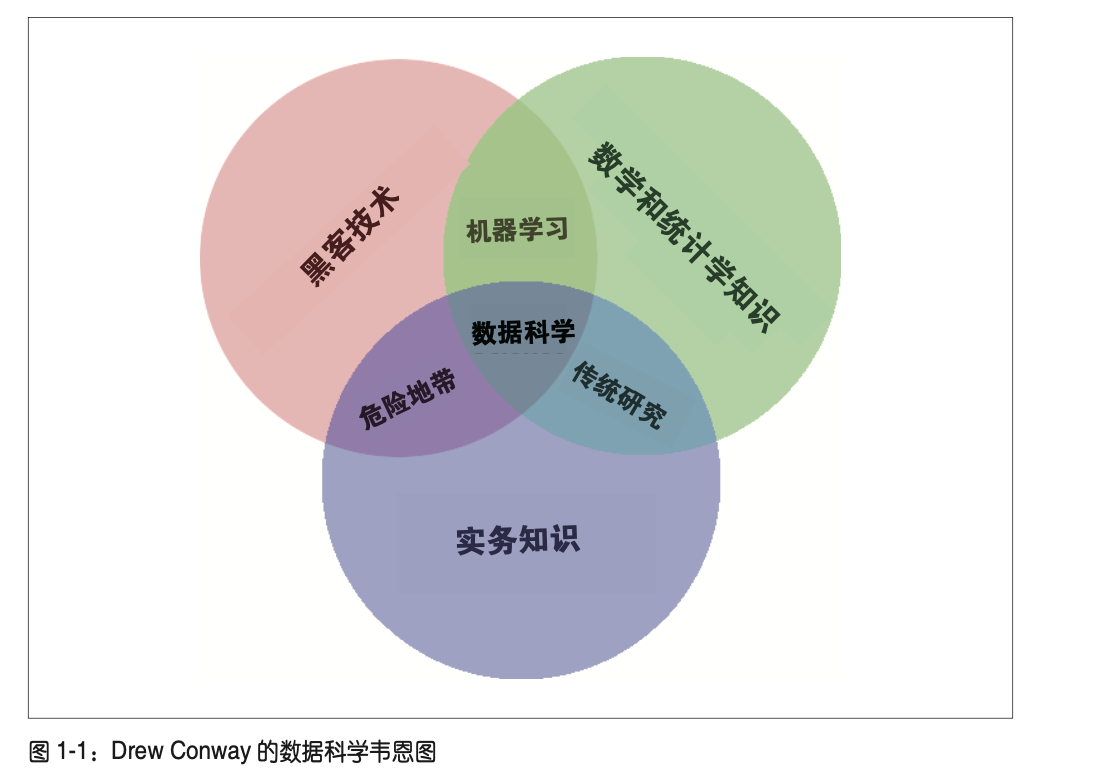
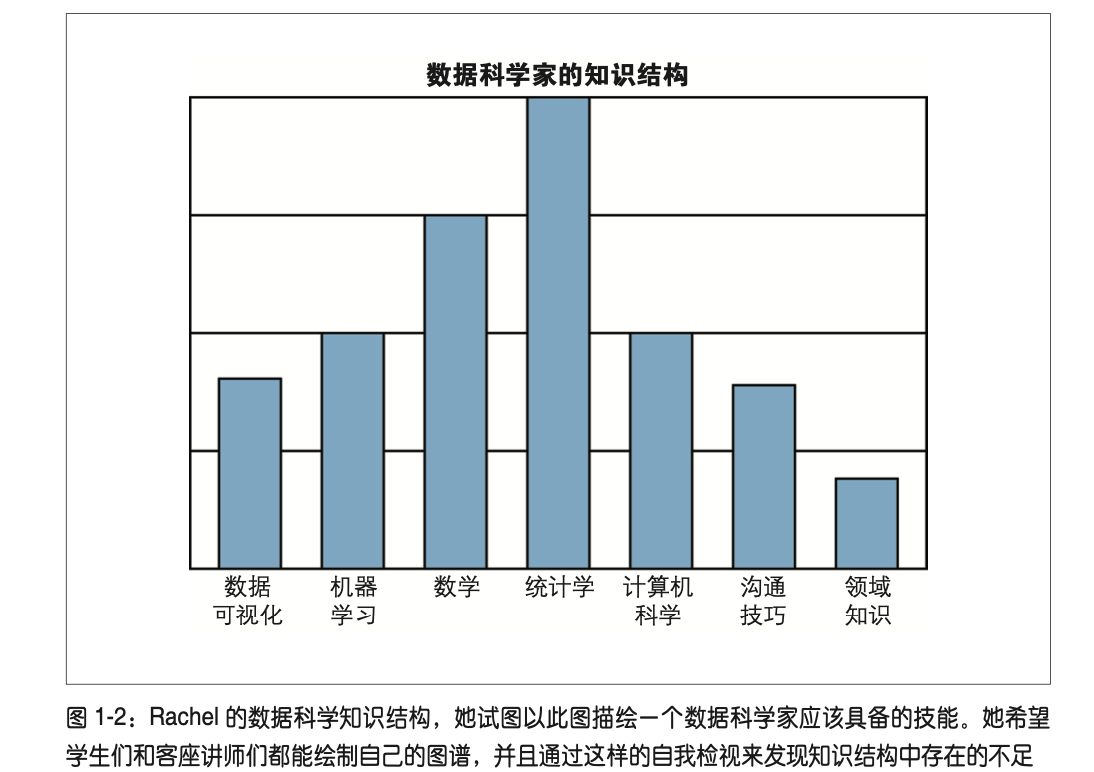
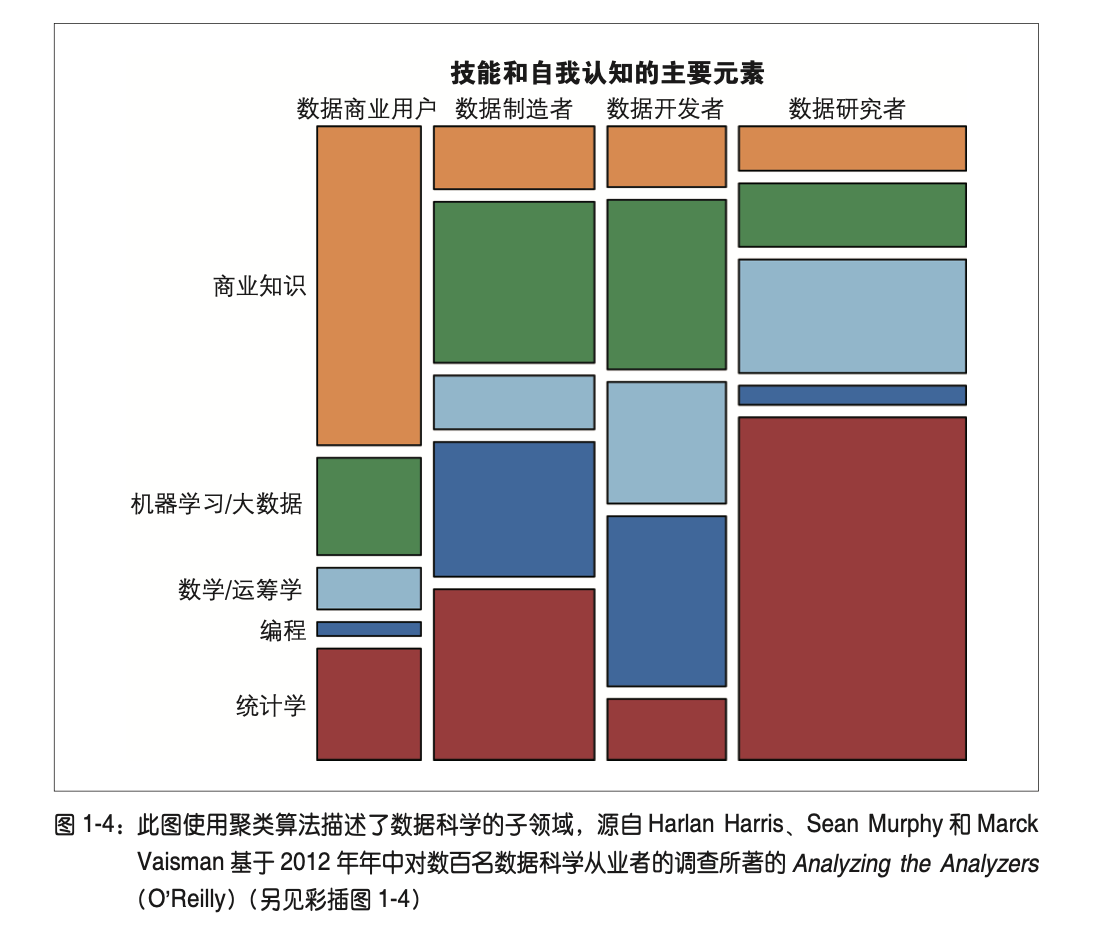
探索性数据分析
探索性数据分析的基本工具是图、表和汇总统计量,是一种系统性分析数据的方法,它展示了所有变量的分布情况、时间序列数据和变换变量,利用散点矩阵图展示了变量两两之间的关系,并且得到了所有汇总统计量。
探索性数据分析不仅是一组工具,更是一种思维方式:要怎么看待和数据之间的关系。你想理解数据,了解数据的形状,获得对数据的直观感受,想将数据和你对产生数据的过程的理解关联起来。探索性数据分析是你和数据之间的桥梁,它不向任何人证明什么。
使用EDA的原因:获取对数据的直觉、比较变量的分布、对数据进行检查(规模、格式等)、数据中的异常值和缺失值、对数据的总结。
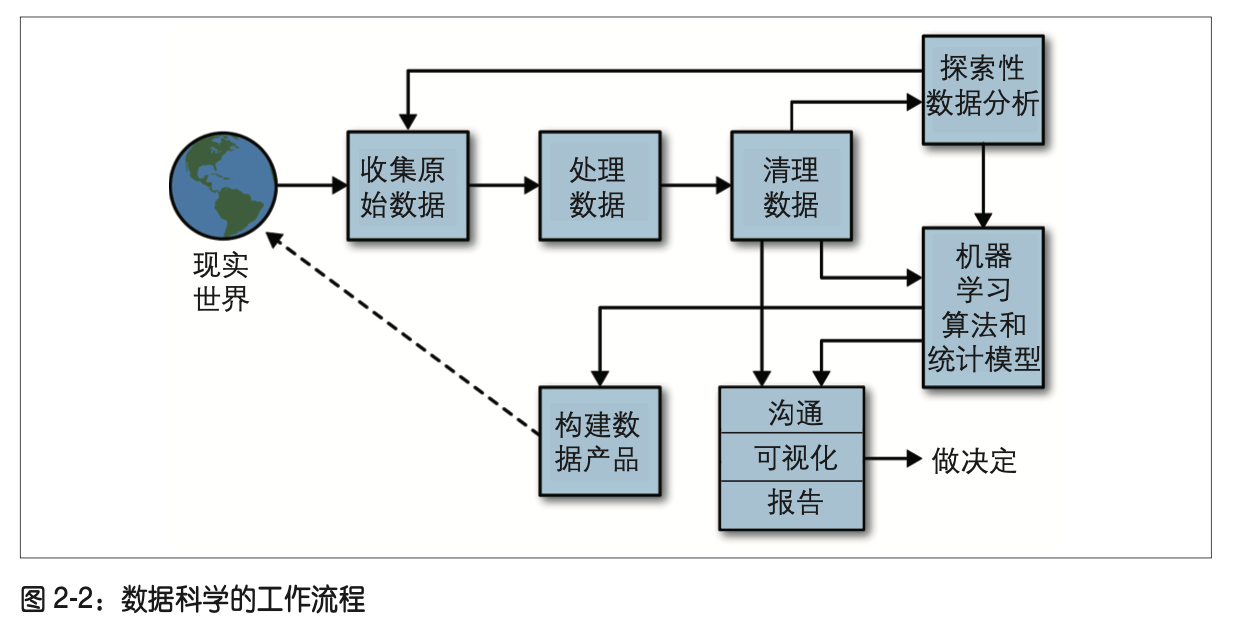
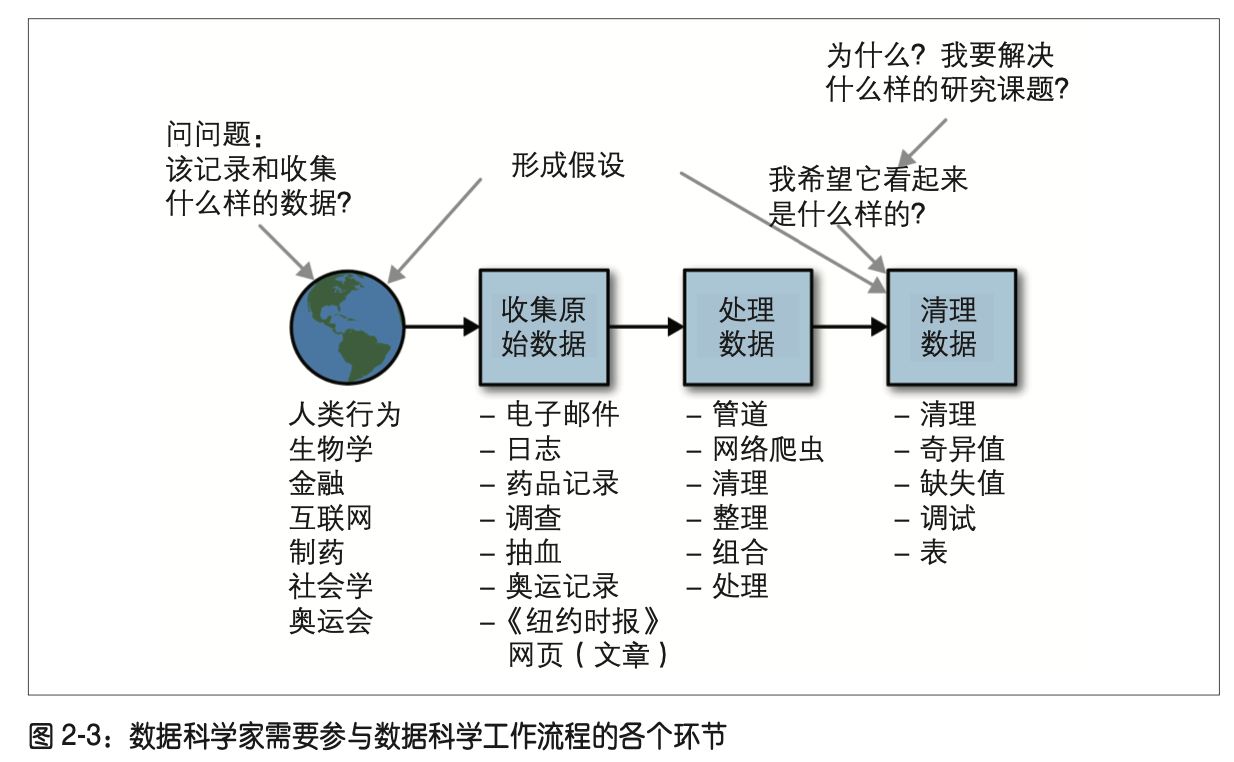
模型选择
模型选择,从最简单开始,逐渐增加复杂度,做出假设并把假设写下来。很多时候,原始简单的模型帮你完成了90%的任务,而且构建该模型只需要几个小时,采用复杂的模型或许会花上几个月,而且只将这个数值提到了92%。
在建模完成之后,你要确保这个模型能够解决最初提出的问题。
- 如果你找到了一个最优的模型,坚持使用它
- 如果你有一个新主意,把它与你之前的最优模型进行比较,通常,你需要思考一下如何设计好对比试验
- 在能够100%确定之前,不停的实验
- 使用哪一个分类器
- 应用何种优化方法训练分类器
- 选择什么样的损失函数
- 哪些特征变量对建模有用
- 如何评估模型的实际效果
在应用模型分析数据的时候,要不时地拷问自己,是不是真的理解你正在使用的模型,以及模型的可解释性。
特征提取
特征提纯是将原始数据中的垃圾信息或者变量删除,让数据更加“干净”,特征选择是在数据提纯之后,根据数据和研究问题的特点,通过提取、重构、组合等方式构造对于建模有用的预测量。
原始数据中存在大量的冗余信息,比如很多相关性很大的变量,这些信息需要经过挑选、转化或组合,才能为模型所用。找有意义的数据,做好基本的清理工作,尝试建模,寻找合理的评价标准,构思有意义的分析问题。
特征提纯和选择对于机器学习的重要性经常被人忽视,但却是其中最为重要的一环。选择更好的特征变量往往可以得到效果更佳的模型。
基础算法
要解决的基本问题是分类和预测,三大基本算法:线性回归模型、k近邻模型、k均值算法。
朴素贝叶斯算法及其应用。
用决策树处理分类问题,在每一步上,都先放上信息量最大的变量,从上往下地搭建决策树。
一些认知
数据理解
深入研究数据的生成过程、模型评价过程,使用各种方法进行建模,包括逻辑回归、k最小近邻算法等,最重要的是将所有的事情都串起来。
数据和领域知识是数据科学家所需具备的最重要技能,但是这些技能是老师教不来的,只能通过不断积累得来。
如何避免数据泄露?暂时去掉那些事先已经知道的信息;每一条记录都应该有一个时间戳,记录你得到该信息的时间,而不是这条记录发生的时间;去掉那些制造麻烦的行和列,特别是那些很容易发现不一致的信息。最后,你需要知道数据到底是如何产生的。
业务开展
大数据研究应该以小数据为起点,先在小数据上建立对问题的基本认知和把握,再延伸到对大数据的整体研究上。反之亦然,在大数据上发现的数据特征,也应该及时地回溯到小数据上进一步验证审查,在一小部分样本人群中做可用性研究。
一个优秀地数据科学团队应该把定量与定性研究、大数据与小数据研究相结合才能取得成功。
作为数据科学家,我们的工作绝不能只停留在描述性统计阶段,应该勇于跨入深水区,设计实验,研究变量之间深层次的关系。这需要我们敢于把工作重心从描述性统计转移到预测模型上来。
当你向大数据迈进的路上,不要被定量分析蒙蔽了双眼。简单的、基于逻辑的定性分析对于更加深刻地理解数据同样重要。
我们应该以问题为导向,而不是被数据牵着鼻子走。先把问题设定好,再找数据并从数据中找到信息。
三个建议:
- 当进行因果推断时,深入地了解数据的生成过程至关重要。因为任何模型都会有相应的模型假设,数据本身的数据生成过程可能会明显背离这些假设。如果假设明显不符合数据的生成模型,那模型的使用就应该打上问号。
- 数据分析的第一步应该置身数据之外,弄清楚到底想要分析的问题是什么。可以把问题写下来,这会帮助你思考,然后再一步一步地思考是用什么样的工具解决这些问题。在使用工具分析数据的过程中,要不时地回头想想当初想要回答的问题,以及正在做的事情是不是在正确的轨道上。这听起来很有道理,也稀松平常,但人们往往都会忘了这么做,忘记了自己分析问题的初衷。
- 最后,当你运用算法分析数据时,不要被算法和代码冲昏了头脑。不要以为算法收敛,模型参数估计显著就一切大吉了。在数据分析时,要时刻保持一颗清醒的头脑,人脑可以发现电脑所不能发现的逻辑性的、常识性的错误;人也应该在数据分析中扮演主导型的角色。
职业观察与思考
数据科学家,是软件工程师里最懂统计的,统计学家里最会编程的。
通过对数据科学家日常工作的观察,Josh发现90%的时间都被用来清理和准备数据。在解决问题和获得洞见之间,数据科学家往往选择前者。更确切地说,从一个问题出发,确保它有值得优化的地方,然后并行化处理所有事情。
模型不免最终沦为疯狂的鲁布·戈德堡机械,一堆模型的大杂烩。这并不总是件坏事,只要模型能工作,就没有问题。即使以一个简单的模型开始,最终还是会添添补补,变得复杂起来。这种事一再发生,没办法,这就是设计模型的本质。
任何单条记录都不是特别有用的,但是拥有所有的记录则价值连城。
抛开问题的上下文和决策流程,单纯学习数据科学需要的统计学工具是没有意义的。而且,真实数据经常是一团乱麻,处理起来令人头疼;现实中也没人告诉你该选择哪种回归模型。但是,仅仅知道这些是不够的,必须通过亲身实践才能理解,纸上得来终觉浅,绝知此事要躬行。
成为解决问题的人
什么时候强调探索性数据分析都为时不晚。数据科学家如何在无数的模型中做出选择——该选用哪种分类器、特征、损失函数、优选法和评价模型的标准。Huffaker讨论了特征或矩阵的构成,从日志中变换变量,构建0-1变量(比如,重复5次同样活动的用户),聚合和计算。虽然这些是数据科学中的关键部分,但经常被认为是微不足道的,因此常常在工作中被忽略了。Dalessandro将这称为“数据科学的艺术”。
另一个警告:很多人拿到数据就直接使用一个花哨的算法。但是在数据和算法之间,还有很长的一段距离。跑一段代码去预测或分类,当算法收敛时就可以宣告取得了成功,这些都很简单。难的是正确地分析和预测,确保结果是正确和说得通的。
下一代数据科学家不会试图用复杂但并不奏效的模型来让自己看起来高深莫测。他们花大量的时间整理数据,大概90%的时间,尽管没人愿意承认这一点。最后,他们不会陷入对某种工具、方法或某个学术部门的宗教式崇拜中,他们多才多艺,在各学科间切换自如。
培养软技能
大多数人开始做得都不是很好,从哪儿开始不重要,重要的是最终能走多远。养成良好的习惯,以开放的心态持续学习是非常重要的。
持之以恒,思考你的大脑是如何思考的,不钻牛角尖,能灵活地思考,永远追求准确度,带有同理心地去思考问题。
让我们换个角度来看这个问题,在传统教育体系中,我们关注的是答案。但我们更应该关注,或者至少应该花更大力气去强调的是学生在面对未知问题时该怎么办。我们需要具备能帮助找出答案的素质。
你是否想过,为什么人们不知道某件事时,不直接说“不知道”?这种现象,可以被部分解释为“达克效应”,无知比知识更容易招致自信。基本上,在某件事上不擅长的人,不知道他们在这件事上有多无知,因此容易高估自己,而那些擅长某事的人,却因为了解,反而低估了他们的能力。知识削弱了人们的自信。将这些谨记在心,不要高估,也不要低估自己,确保说到的东西可以做到,和其他数据科学家交谈时不要忘记随时检查自己。
成为提问者
习惯遵循一份包含关键步骤的标准清单:非要这样做不可吗?如何衡量它?哪种算法适合这个问题,为什么?我该如何评价它?我真的具备做这件事的技术吗?如果没有,我该如何学习这些技术?我可以和谁一起工作?有问题可以问谁?对现实世界有何影响?最后这个可能是最重要的一个问题。
其次,习惯向别人提问。当你遇到一个问题或某个人,需要提出问题时,先假设自己是聪明的,不要认为回答的人比你知道得多或者少。不要试图去证明什么,你的目的是找到答案。像个孩子那样充满好奇心,别怕自己看起来很笨。要求澄清一些符号、术语和流程:数据从哪里来?如何使用这些数据?为什么这些数据能用?我们忽略了哪些数据,这些数据包含更多特征吗?谁该干什么?如何一起合作?
最后,有一个特别重要的概念要时刻牢记,那就是因果关系和相关关系。不要将二者混为一谈。也就是说,当你看到相关关系时,不要误以为那是因果关系。
用户交互
要牢记用户行为产生的数据已经构成了数据产品的一部分,反过来数据产品又被用户使用,影响用户的行为。
- 时刻谨记这个世界不是由我创造的,它不必符合我的方程式。
- 虽然可以大胆地使用模型做预测,但切不可过分迷信数学。
- 我绝不会牺牲真实换来优雅的数学模型,并且拒绝解释这样做的原因。我也不会在模型的准确度上欺骗我的用户,相反的,我会如实陈述模型的假设条件和模型的局限性。
- 我知道我的工作对于社会和经济影响巨大,其中很多已经超出我的理解能力。
你的目标
- 你选择什么样的生活。要回答这个问题,你需要清楚自己看重什么。你的目标是什么?你想追求什么?你想成名吗?你想受人尊敬,并且学有所长吗?或许你的最佳选择是上述几种情况的某种组合,那么现在,你清楚地知道你的选择了吗?
- 你有哪些局限。有很多外在因素,或许是你无法左右的,比如你无法选择和家人住在哪里。还有金钱和时间上的限制,你是否需要研究公司的年假、产假和陪产假政策。向用人单位推销自己难度几何?不要被逼入绝境,想想如何展示自己积极的一面:学历、优缺点、能改变的和不能改变的。
应用
技能自评
| 技能 | 自评 | 技能点 | 注释 |
|---|---|---|---|
| 数据可视化 | |||
| 机器学习 | |||
| 数学 | |||
| 统计学 | |||
| 计算机科学 | |||
| 沟通技巧 | |||
| 领域知识 |
参考
- O’neil, Cathy, and Rachel Schutt. Doing Data Science. O’reilly, 2013.
附件
几份技能自评报告与技能星形图
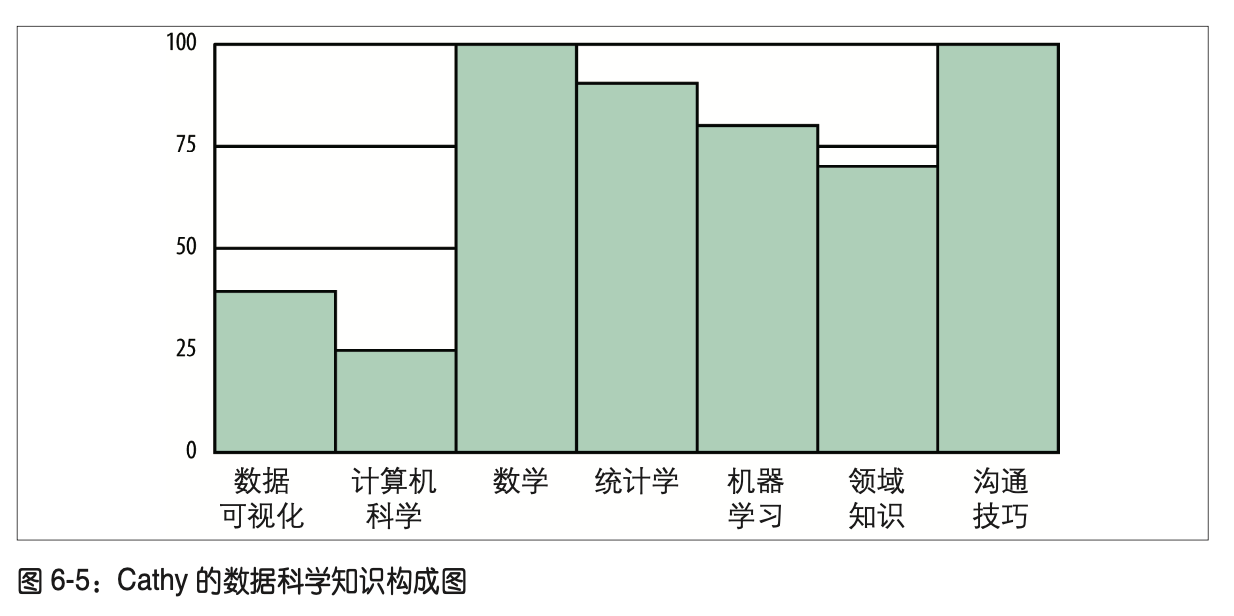


数据科学家的知识结构的原始材料
- 探索性数据分析;
- 可视化(用在探索性数据分析和汇报中);
- 数字面板和矩阵;
- 对业务的洞察力;
- 数据驱动决策;
- 数据工程和处理大数据的能力(Mapreduce、Hadoop、Hive、Pig);
- 收集数据;
- 构建数据管道(日志 -> mapreduce -> 数据文件 -> 同其他数据合并 -> mapreduce -> 清除一些噪声 -> 合并);
- 开发新产品,而不仅仅停留在对现有产品的使用进行描述上;
- Hack;
- 写专利;
- 数据侦探;
- 预测未来的行为或性能;
- 将发现写成报告、做演讲或发表在学术期刊上;
- 编程(要熟练使用R、Python、C和Java等语言);
- 条件概率;
- 优化;
- 算法、统计模型和机器学习;
- 讲故事的能力;
- 会提问题;
- 做调查;
- 搞研究;
- 从数据中做出推测;
- 开发数据产品;
- 找到数据处理的方法,会根据数据规模改变分析策略;
- 一致性检查;
- 对数据的直觉;
- 和领域专家打交道的能力(或者让自己成为一个领域专家);
- 设计和分析实验;
- 发现数据间的相关性,并且尝试建立潜在的因果关系。
数据科学应用在哪里或哪个领域并不重要,它的关键是通过算法和代码定义了一套从“题域”到“解域”的映射,而数据是关键中的关键。
版本记录
2024-07-14,初稿;